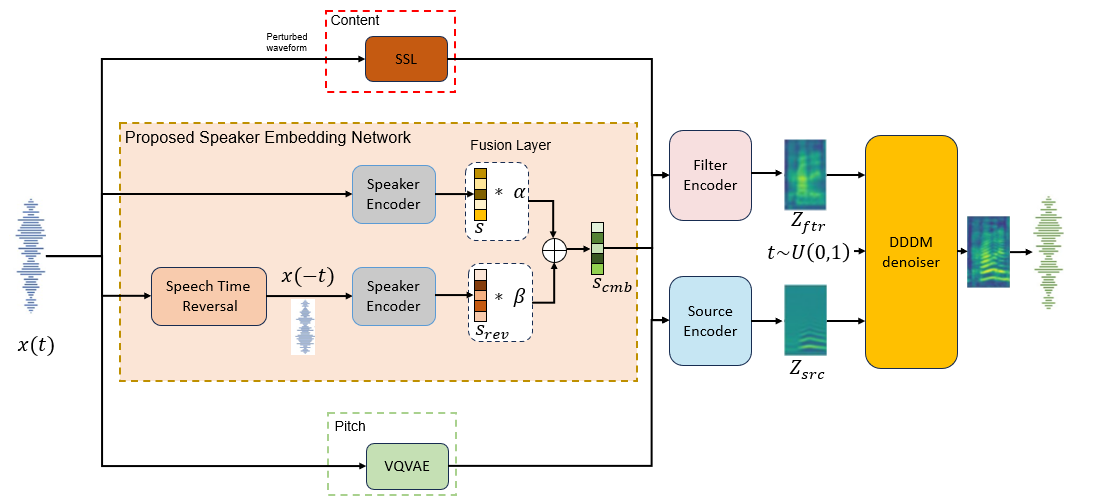
Figure 1: Blockdiagram of the propose approach in Diffusion-based Voice Conversion.
Speech time reversal refers to the process of reversing the entire speech signal in time, causing it to play backward. Such signals are completely unintelligible since the fundamental structures of phonemes and syllables are destroyed. However, they still retain tonal patterns that enable perceptual speaker identification despite losing linguistic content. In this paper, we propose leveraging speaker representations learned from time reversed speech as an augmentation strategy to enhance speaker representation. Notably, speaker and language disentanglement in voice conversion (VC) is essential to accurately preserve a speaker's unique vocal traits while minimizing interference from linguistic content. The effectiveness of the proposed approach is evaluated in the context of state-of-the-art diffusion-based VC models. Experimental results indicate that the proposed approach significantly improves speaker similarity-related scores while maintaining high speech quality.
accepted at INTERSPEECH 2025
Figure 1: Blockdiagram of the propose approach in Diffusion-based Voice Conversion.
| Methods | Sample 1 | Sample 2 | Sample 3 |
|---|---|---|---|
| Source | |||
| Reference | |||
| DDDM-VC | |||
| DDDM-VC + Ours | |||
| DiffHier-VC | |||
| DiffHier-VC + Ours | |||
| Diff-VC | |||
| Diff-VC + Ours | |||
| LMVC | |||
| SEFVC | |||
| StyleVC | |||
| StableVC | |||
| VALLE VC |
@inproceedings{rewind2025,
title={REWIND: Speech Time Reversal for Enhancing Speaker Representations in Diffusion-based Voice Conversion},
author={Biyani, Ishan and Shah, Nirmesh and Gudmalwar, Ashishkumar and Wasnik, Pankaj and Shah, Rajiv Ratn},
booktitle={INTERSPEECH},
year={2025}
}