Introduction
Despite significant progress in the field of Generative AI, speech synthesis models still encounter several challenges when it comes to the AI-based dubbing of entertainment content such as movies and serials. AI-based dubbing involves replicating input speech emotion and controlling its intensity depending on the context and emotion of the scene. Most of today’s text-to-speech (TTS) systems can produce high-quality, high-fidelity, natural speech output, but they still lack expressiveness and fine control over emotional states. The Emotional Voice Conversion (EVC) aims to convert the discrete emotional state from the source emotion to the target for a given speech utterance while preserving linguistic content. In this paper, we propose regularizing emotion intensity in the diffusion-based EVC framework to generate precise speech of the target emotion. Traditional approaches control the intensity of an emotional state in the utterance via emotion class probabilities or intensity labels that often lead to inept style manipulations and degradations in quality.
To address these issues, we introduce the following components:
- Direction Latent Vector Modelling (DVM): We propose a novel DVM for obtaining fine control over intensity while transitioning across different emotional states.
- SSL Framework: The proposed EmoReg utilizes the SSL-based audio feature representations, which are obtained after finetuning the SSL-based framework for a downstream task related to emotion classification.
- Diffusion-based VC: These emotion embeddings can be modified based on the given target emotion intensity and the corresponding direction vector. Finally, the updated embeddings can be fused in the reverse diffusion process to generate speech with the desired emotion and intensity value.
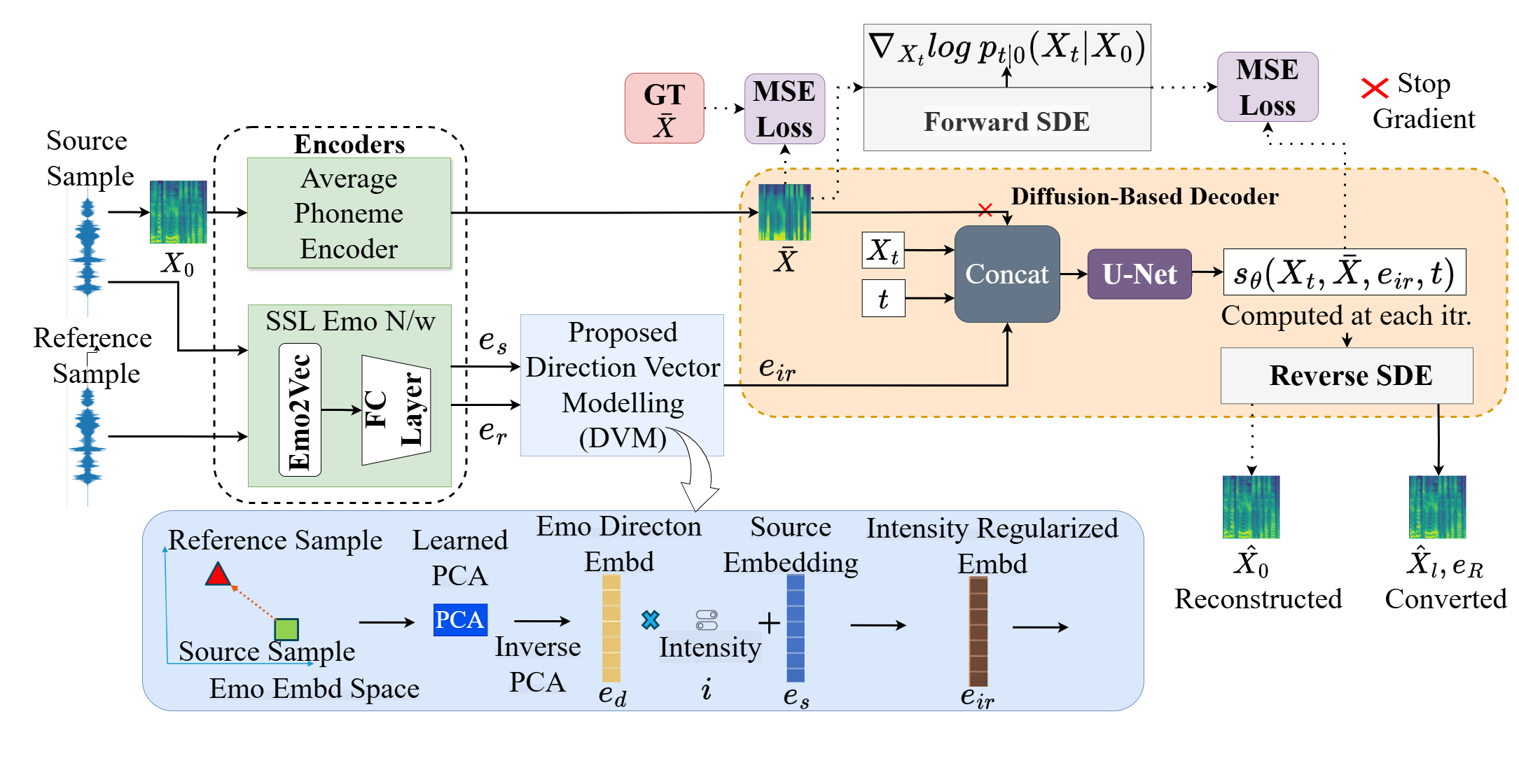
Figure 1: Block diagram of the proposed DVM-based Emotion Intensity Regularized EVC architecture. Dotted arrows represent operations performed only during training. Also, GT ̄X are derived by replacing each phoneme Mel-spectrogram feature in the input with its corresponding pre-calculated average feature.
Results
The emotion similarity score for emotion voice conversion is calculated for Neutral-to-Angry, Neutral-to-Sad, and Neutral-to-Happy emotion conversion scenarios for the proposed approach and baseline methods. Table 1 illustrates the comprehensive evaluation of the proposed EmoReg with DVM outperforms all the SOTA approaches in the EVC task.
Table 1: Analysis of emotion similarity scores along with margin of error corresponding to the 95% CI.
| Methods |
Neu-Ang ↑ |
Neu-Sad ↑ |
Neu-Hap ↑ |
Average ↑ |
| Emovox |
0.94 ± 0.004 |
0.94 ± 0.004 |
0.95 ± 0.004 |
0.94 ± 0.004 |
| Mixed Emotion |
0.94 ± 0.004 |
0.92 ± 0.004 |
0.90 ± 0.004 |
0.92 ± 0.004 |
| CycleGAN-EVC |
0.96 ± 0.004 |
0.92 ± 0.004 |
0.91 ± 0.004 |
0.93 ± 0.004 |
| StarGAN-EVC |
0.95 ± 0.004 |
0.91 ± 0.004 |
0.91 ± 0.004 |
0.93 ± 0.004 |
| Seq2Seq-EVC |
0.96 ± 0.004 |
0.93 ± 0.004 |
0.87 ± 0.004 |
0.92 ± 0.004 |
| StyleVC |
0.96 ± 0.004 |
0.92 ± 0.004 |
0.91 ± 0.004 |
0.93 ± 0.004 |
| DISSC |
0.88 ± 0.004 |
0.91 ± 0.004 |
0.87 ± 0.004 |
0.89 ± 0.004 |
| Ablation |
0.96 ± 0.004 |
0.93 ± 0.004 |
0.95 ± 0.004 |
0.94 ± 0.004 |
| Proposed |
0.97 ± 0.003 |
0.96 ± 0.003 |
0.95 ± 0.003 |
0.96 ± 0.003 |
The effectiveness of the proposed approach is evaluated across different databases using similar objective and subjective assessments for both English and Hindi languages. Table 2 shows the emotion similarity scores for Neutral-to-Angry, Neutral-to-Sad, and Neutral-to-Happy emotion voice conversion for ablation and the proposed EmoReg approach for both languages. It is evident from Table 2 that the proposed approach also performs well for the Hindi language.
Table 2: Emotion Similarity scores across languages along with 95% confidence interval.
| Methods ↑ |
Neu-Ang ↑ |
Neu-Sad ↑ |
Neu-Hap ↑ |
Avg ↑ |
| English |
| Ablation |
0.96 ± 0.004 |
0.93 ± 0.004 |
0.95 ± 0.004 |
0.94 ± 0.004 |
| Proposed |
0.97 ± 0.003 |
0.96 ± 0.003 |
0.95 ± 0.003 |
0.96 ± 0.003 |
| Hindi |
| Ablation |
0.89 ± 0.003 |
0.86 ± 0.003 |
0.89 ± 0.003 |
0.88 ± 0.003 |
| Proposed |
0.91 ± 0.003 |
0.87 ± 0.003 |
0.87 ± 0.003 |
0.88 ± 0.003 |
The performance of the EmoReg approach is further investigated on different intensity scores using emotion similarity score, as shown in Figure 2. We used an intensity scale range of 0 to 1 with a 0.2 step size and we could only consider EmoVox and MixedEmotion models, as others i.e., CycleGAN-StarGAN-EVC and Seq2Seq-EVC lack support for emotion intensity regularization due to their architectural limitations. Additionally, from Figure 2, it is apparent that the emotion similarity score increases with an increase in emotion intensity scale which shows that the proposed EmoReg with DVM can achieve fine control over emotion intensity. Whereas, the emotion similarity score of the baselines and ablation does not vary with an increase in intensity scale and hence, fails to achieve fine control over emotion intensity.
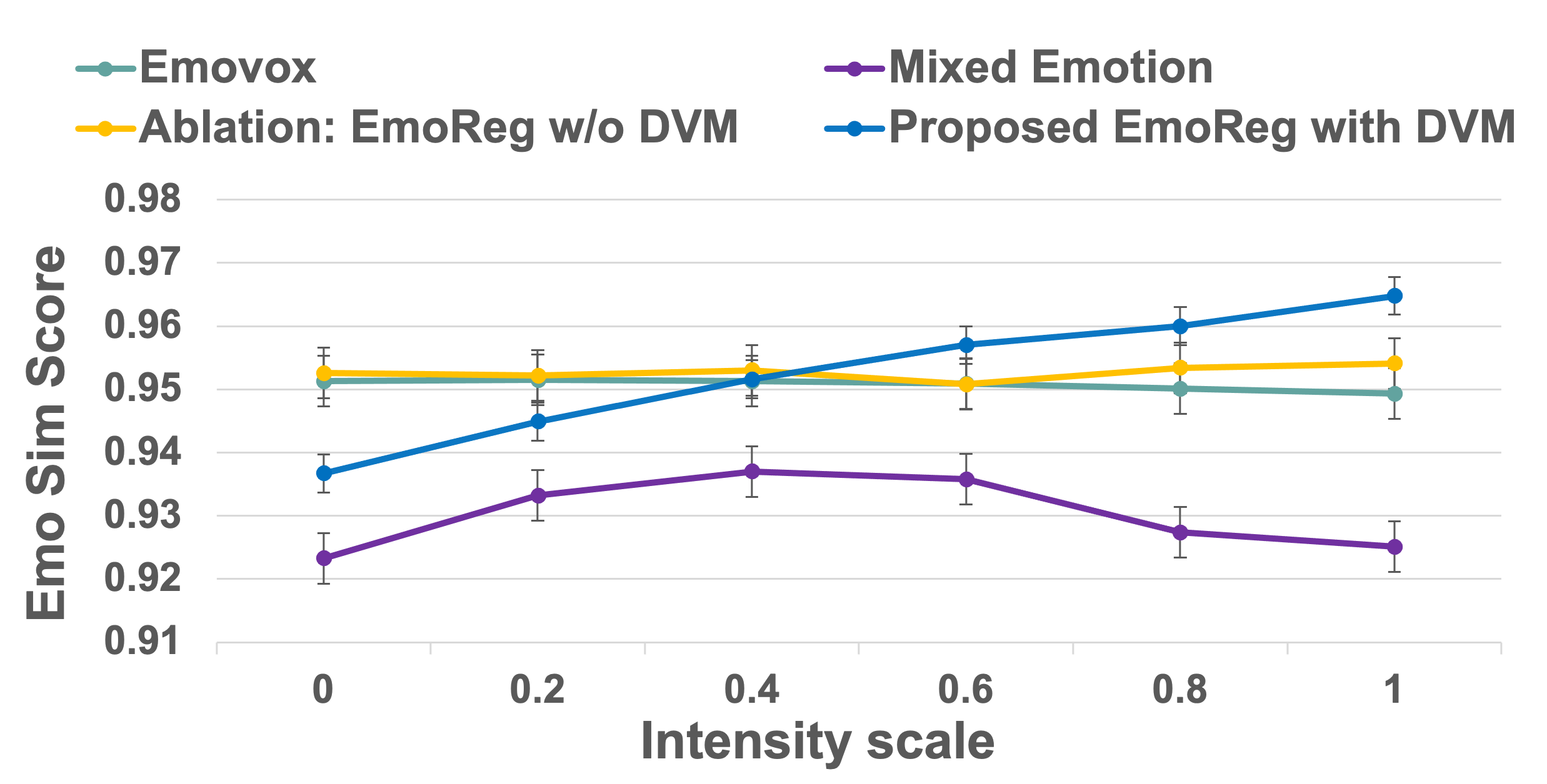
Figure 2: Analysis of emotion similarity score with respect to incremental emotion intensity scale.
Conclusion
We introduced the EmoReg model for emotion voice conversion with emotion intensity regularization. By leveraging SSL-based emotion embeddings, we achieved effective emotion representation from speech. We proposed a DVM to transition between emotional states while controlling emotion intensity. We evaluated our approach against the SOTA architectures for both English and Hindi languages. In summary, the proposed EmoReg model outperformed existing methods in various objective evaluations.
Citation
@inproceedings{emoreg2025,
title={EmoReg: Directional Latent Vector Modeling for Emotional Intensity Regularization in Diffusion-based Voice Conversion},
author={Gudmalwar, Ashishkumar and Biyani, Ishan and Shah, Nirmesh and Wasnik, Pankaj and Shah, Rajiv Ratn},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2025}
}